
In previous posts, we have introduced exemplary machine learning algorithms for common real-world problems. We e.g. introduced optimization for shallow learning and deep learning models. In this article, we want to clarify the three main paradigms of machine learning.
These paradigms are supervised, unsupervised, and reinforcement learning.
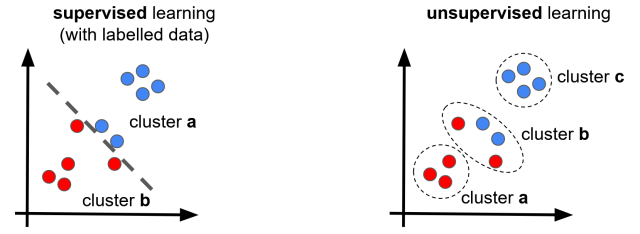
Supervised machine learning algorithms
Supervised machine learning algorithms train models based on a dataset containing input and output data. In other words this data is labelled. Labels have been assigned to the data before training the model, and in supervised learning models the aim is basically to predict the labels without knowing them, based on the input data. This is done using a training set of data.
Supervised machine learning algorithms improve models by minimizing the deviation between model predictions and actual output values for given input values. This approach is feasible since, in these cases, information on the output values is available.
In other words, for supervised machine learning, the outcome (i.e., the results) to actions and causes is known, and a predictor is optimized to minimize deviations between predicted vs. actual values. Experts, i.e., the supervisors, can also conduct this “tagging” of the input data.
Examples of supervised machine learning algorithms are:
- linear regression
- logistic regression
- support vector machine
- k-nearest neighbor
- decision tree

Advantages of supervised machine learning
- High degree of control. The model trainer provides the data and thereby controls what the model will learn.
- Easy and intuitive to understand. The concept of fitting predictions to training data is a concept most people easily grasp.
- Appropriate for understanding relationships between input and output data, if both can be provided.
Disadvantages of supervised machine learning
- By definition, supervised learning models must be provided with both input and output data.
- Supervised machine learning algorithms require a set of data with inputs and outputs to train on. This data can be hard to obtain or create.
- Even if that data is obtainable, the supervised learning algorithms will not perform better than the training data itself. If, for example, the supervised learning model is trying to replicate the actions of a human player, then the model will aim at replicating that human player’s actions and thereby also his or her performance. Still, it will, in the best case, perform just like the human player.
- A model developer might want the model to outperform the human player and in that case supervised machine learning is not the right paradigm (see reinforcement learning).
- There is always the risk of overfitting models and predictions.
- Supervised learning requires manual algorithm selection. That is, given the problem, one has to select the correct algorithm to apply manually.
Unsupervised machine learning algorithms
Unsupervised learning algorithms are usually applied to problems such as, e.g.:
- k-means clustering
- hierarchical clustering
- principal component analysis
- local outlier factor
- isolation forest
- deep belief nets
In the case of unsupervised learning, information is available for the input of the model. The related output information is not available, meaning no direct relationship between input and output is available from the data. In other words, the data is “untagged.” Unsupervised machine learning algorithms are used to understand data patterns and structures and gain additional insights from the data.
Advantages of unsupervised learning
- Does not require data to be tagged.
- Appropriate methodology for clustering and finding patterns and structures in raw untagged data.
- Can be used as a pre-processing step before labeling data for a supervised learning run, thereby making some supervised learning applications perform better.
- Can be used for dimensionality reduction, beneficial when the number of features for supervised learning is high.
Disadvantages of unsupervised learning
- Often more time-consuming and trial and error based computation compared to supervised learning.
- Compared to a model trained on labeled data, the results, e.g. the identified patterns, might be less accurate.
Reinforcement machine learning algorithms
In the case of reinforcement learning, there is no known output data and no known input data. That is, the environment is unknown. There is no input data to create a pattern from, and there is no output data to derive a relationship to (as in the case of e.g. regression analysis). Reinforcement learning algorithms therefore use an iterative approach for improving their decision-making, learning from their previous actions and experiences.
The core of any reinforcement algorithm is a decision-making policy that describes what actions are taken in what state. Based on that policy, a set of rewards will be harvested and evaluated against an adjusted policy leading to different actions in different states. Such policies are tested in iterative runs, often also referred to as games and side games.
Some examples of reinforcement learning are:
- deep q network

Advantages of reinforcement machine learning
- Does not require training data to work.
- Can be used in uncertain environments with little information.
- Models improve with experience.
- Models can perform better than the human who wrote them, as e.g. already demonstrated by A. L. Samuel in 1959 with a chess-playing algorithm
Disadvantages of reinforcement machine learning
- Simpler problems might better be solved with a supervised or unsupervised machine learning approach.
- Might require a lot of computational power.
- Assumes, at its core, that the environment is a Markovian model with states and probability-based state transitions; this might not always be practical.
- The cost of learning can be high, especially if the learning agent is e.g. a robot that needs to learn over long periods and also may require e.g. hardware maintenance.

Data scientist focusing on simulation, optimization and modeling in R, SQL, VBA and Python



Leave a Reply